WAV or WAVE is one of the most common audio file formats. In this post, we’ll see how to access the information stored in the header of a wave file. We’ll start by taking a look at the header’s format, and what data it stores. Then, we’ll see how to read this information with a program written in C.
You can access an overview of WAV file characteristics at VideoProc’s site.
WAV header
For this post, and the program implementation we’ll see below, we’ll concentrate on the simplest possible header format for wav files. We’ll use the same names for the header fields as described in the soundfile++ library documentation.
The header information starts at the beginning of the wave file (byte offset 0). The first 4 bytes are used to encode the characters RIFF, which refers to the container format used for wave files. Following it, we’ll have fields of either 4 or 2 bytes long that represent more information. We’ll not get into the details of the header format as it has been well explained before (also here).
The most important features are that the header is 44 bytes long and that it’s divided into fields of 2 or 4 bytes long. These fields are either strings, such as RIFF, or numerical values. The numerical values are either 2 or 4 bytes long and they are encoded in little-endian ordering (more information on the ordering below).
An example of the contents of the header for a wave file can be found below.
| Name | offset | Size | Value |
|---|---|---|---|
| ChunkID | 0 | 4 | “RIFF” |
| ChunkSize | 4 | 4 | 405040 |
| Format | 8 | 4 | “WAVE” |
| Subchunk1 ID | 12 | 4 | “fmt” |
| Subchunk1 Size | 16 | 4 | 16 |
| Audio Format | 20 | 2 | 1 |
| Num Channels | 22 | 2 | 2 |
| Sample Rate | 24 | 4 | 22050 |
| Byte Rate | 28 | 4 | 88200 |
| Block Align | 32 | 2 | 4 |
| Bits per Sample | 34 | 2 | 16 |
| Subchunk2 ID | 36 | 4 | “data” |
| Subchunk 2 Size | 40 | 4 | 405004 |
Now that we’re familiar with the header structure, we can start describing the implementation.
Header struct
The main way we’ll access the bytes of the header is by using a struct. This will instruct C to allocate a contiguous space in memory large enough to contain all of the variables that form the struct.
struct header_struct {
char chunk_id[4];
union int_data chunk_size;
char format[4];
char subchunk1_id[4];
union int_data subchunk1_size;
union short_data audio_format;
union short_data num_channels;
union int_data sample_rate;
union int_data byte_rate;
union short_data block_align;
union short_data bits_per_sample;
char subchunk2_id[4];
union int_data subchunk2_size;
};
See that the numerical fields are implemented using theunion int_data and union short_data data types. We’ll explain them in the section about endianness below.
While in this case it’s not relevant, there are some memory-address alignment requirements that could introduce extra bytes for padding and alignment between variables in the struct. Usually, we require a data type of size t bytes to be in a memory address that’s a multiple of t. Luckily, the wave header can be adequately aligned in memory without having to add padding bytes so we don’t need to concern about this.
Allocating header bytes
The bytes stored in the wave file header will be read byte-by-byte and stored in an array. In C, the char data type is one byte long. We’ll use this data type to fetch the data byte-by-byte. We will alias the unsigned char data type byte to reflect this.
typedef unsigned char byte;
The 44 bytes of the header data will be retrieved in an array. Those same bytes represent the header information described by the struct header_struct data type. To read the data as an array of chars and then reuse that same data as the header, we’ll use a union.
union header_data {
byte data[HEADER_SIZE];
struct header_struct header;
};
This will permit us use the same space in memory both to retrieve the information as an array of bytes and as the struct that was defined above.
Numerical data types sizes
The size of the numerical data fields in the header is either 2 or 4 bytes long. The size of some C data types such as int depends on the implementation (int can be 2 or 4 bytes long). For our program, we’ll rely on the fact that on 64-bit x86 machines int and short are 4 and 2 bytes long respectively. We’ll verify this in the program using the sizeof function.
// Verifying int is 4 bytes long
if (sizeof(int) != 4) {
fprintf(stderr, "Error: machine data type INT isn't 4 bytes long\nCan't process wav header ");
exit(4);
}
An alternative for this program to work across all implementations is to use the fixed size C data types.
Big and little-endian
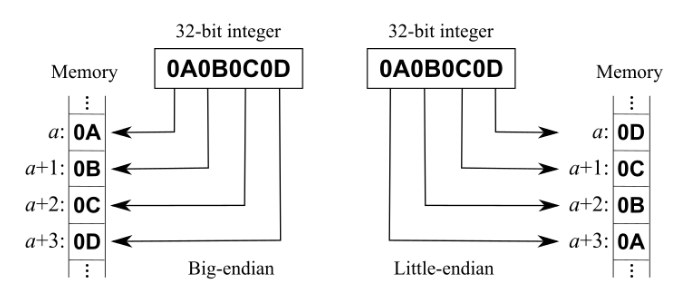
Besides the length in bytes of numerical data, another fact that needs to be considered is the order in which these bytes are stored. In the wave file header, all of the numerical values are stored in little-endian ordering. This means that the bytes are stored starting from the least significant bytes first. The figure below illustrates the difference in byte-ordering between big-endian and little-endian.
{kind=link}
{kind=link}
The value considered above is 0x0A0B0C0D. The initial 0x denotes that the value is in hexadecimal base. Each byte is 2 hexadecimal digits long, so we have 4 bytes: 0A, 0B, 0C , and 0D.
The wav file stores this information in little-endian ordering, that is, starting from the least significant byte first (memory address a in the figure above). That is the order in which the bytes will be retrieved in the data array.
Each machine has its own way of ordering numerical data. No extra steps will be required for machines that store it with the little-endian ordering, as the data will be retrieved in the same ordering. For machines that use big-ending ordering, however, we’ll require to reverse the ordering of the numerical fields.
if (is_bigendian()) reverse_numerical_bytes(file_bytes);
In order to be able to access the bytes of the numerical fields and reverse them, we’ll use union data types again:
union int_data {
int int_value;
byte int_bytes[4];
};
union short_data {
short short_value;
byte short_bytes[2];
};
This way we’ll be able to manipulate the bytes when necessary. Once that’s done, we can just retrieve that same information as either int or short data types.
Retrieving bytes from the wave file
With the data types that will be used to store the data defined, we can begin to retrieve the data. As it was expressed before, we’ll do it byte-by-byte, as it would be done for a regular text file. The only difference is that the data is stored inside a union.
fp = fopen(wav_file, "r"); union header_data *file_bytes = (union header_data *) malloc(sizeof(union header_data)); int i; for (i = 0; i < HEADER_SIZE && (file_bytes->data[i] = getc(fp)) != EOF; i++) ;
Retrieving header information
Once the bytes have been read from the header, the struct type defined above will take care of organizing them as required. We can access them directly.
// union header_data *file_bytes
printf("ChunkID: %.4s\n", file_bytes->header.chunk_id);
printf("ChunkSize: %d\n", file_bytes->header.chunk_size.int_value);
...
The result
Now that the most relevant parts of the implementation have been explained, we can present the results for an example wave file.
$ ./wave test.wav ChunkID: RIFF ChunkSize: 405040 Format: WAVE Subchunk1 ID: fmt Subchunk1 Size: 16 Audio Format: 1 Num Channels: 2 Sample Rate: 22050 ByteRate: 88200 Block Align: 4 Bits per sample: 16 Subchunk2 Id: data Subchunk2 size: 405004
You can acess the complete program here.